
As you clap eyes on the data loading process, you get transfixed to the easy-and-smooth action. This is about a single ETL being created to load data from two different sources shaping up as a visual story on the Microsoft Azure Data Factory interface (and other ETL tools) that keeps you glued. This ADF staged process underlines the significance of Metadata, and that’s reason enough to cue in the pipeline to load tables. Metadata driven ETL is the modern version of ETL redefining data loading and data integration.
Only that Metadata driven ETL based data integration has steered enterprises to reconcile with the data-intensive business demands, slashing down time and effort required to meet the demands. Sample this scenario.
At a Telecom company, this is the crux of the customer-ETL-Billing story. For this customer, the development period was consuming 60 days. This required feeding of data from multiple source systems wherein 25 million records were to be fed from 40,000 files. ETL management was proving to be a challenge-ridden process. Adopting the Metadata driven ETL framework, the Telecom company has achieved significant reduction in the development time which only consumes 10 days, now.
What is Metadata driven ETL?
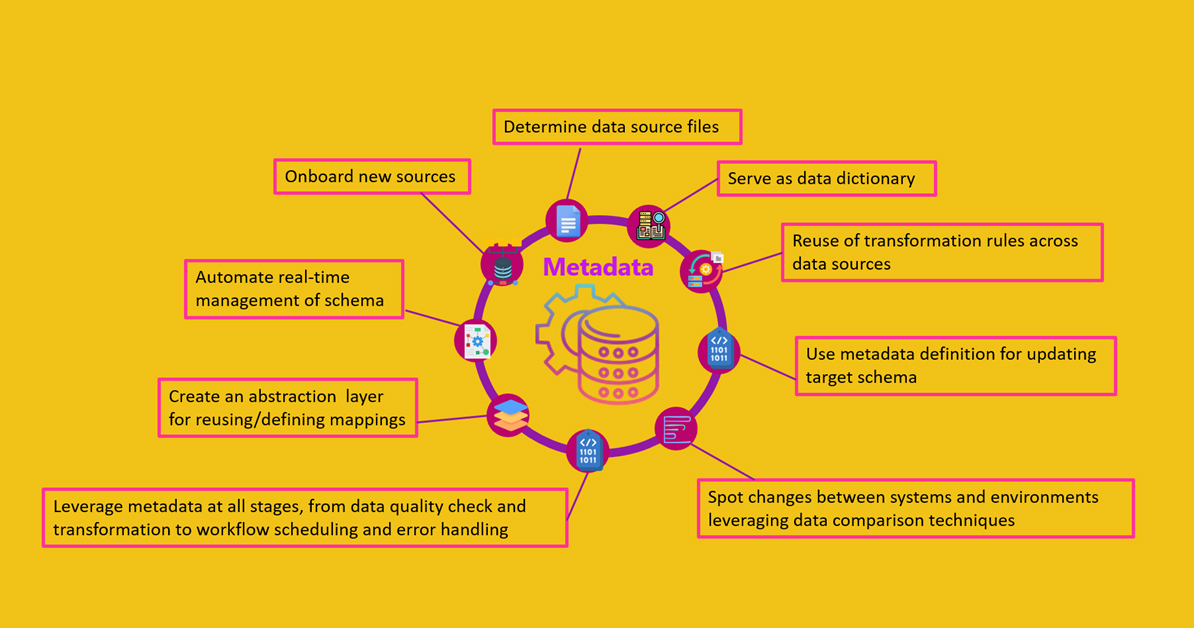
The Metadata driven ETL for data integration standardizes incoming data, allows onboarding of different data sources into DWH, and accelerates ETL development. It facilitates automation with real-time schema management.
In simpler terms, you can decide which data to be processed into a system (in terms of data loading) based on the metadata. Using the existing schema as the context, or leveraging source-system metadata as the reference point, new ETL development can be accelerated. This is followed by easy integration with SQL environments (and NoSQL environments too). You can do away with the need to develop ETL code for loading data.
How Does the Metadata driven ETL Framework Work?
The Metadata driven ETL framework puts emphasis on templates created for:
- Rules management, data migration controls and exception handling
- Integration and transformation rules
As part of the framework, you can store data schemas, data source locations, job control parameters, and error handling logic in configuration files. By this way, you can achieve quick replication and addition of new sources. The key element which is at the central point is the metadata portion enabling the reuse or definition of mappings, definition of different targets and sources, and reuse or definition of transformation rules.
Take this scenario for instance. In the world of clinical research, an institution faces the requisite of creating research data marts – with data requirements varying for the different data marts. The real challenge lies in dealing with the different ontologies and data models used by research data networks. Changing the approach from maintaining logic for every ETL process, they have embraced the metadata-driven ETL concept. Leveraging research data networks and using i2b2, metadata (the core) was acquired from the data schema design & ontology pertaining to i2b2.
Here’s how metadata becomes the controller to organize the transfer of data from source tables to the destination table, without every individual data source being subjected to an individual data transformation process.
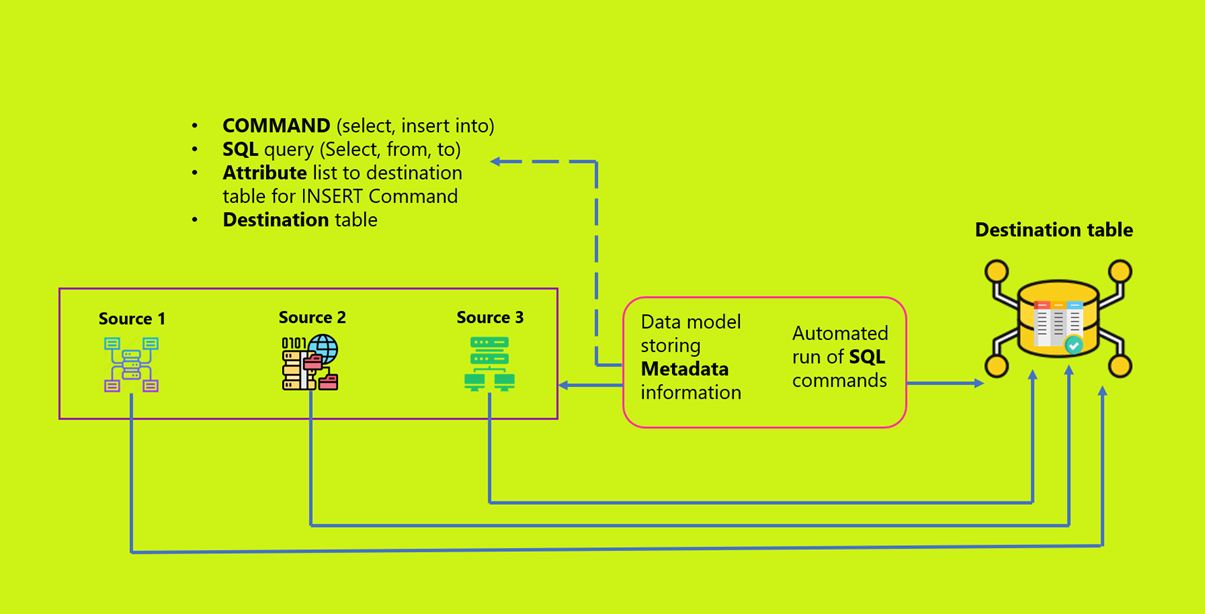
How Metadata driven ETL Slashes Development Time?
Instead of creating a rationale for process, we are creating a process with a rationale to accommodate different data integration scenarios. With the ETL kept at a generic level, it becomes easier to regulate data sources and source files, reuse transformations and mappings, paving the way for faster ETL engineering time.
The figure captures the salient features of the Metadata driven ETL that empowers enterprises with faster development time.
Traditional vs Metadata driven DWH
The use of Metadata driven ETL to load data warehouse scores over the traditional ETL methods in many ways. Here is a comparison chart that captures significant differences between the two.
| Traditional | Metadata driven DWH |
| Engineering of data load ETL, Quality management ETL, data profiling takes significant efforts | Leveraging Metadata to parameterise and automate the engineering of individual ETLs saves substantial time |
| Coordination of ETL changes with schema changes necessitates extreme efforts | Metadata acts as the core of the solution with changes to the design getting propagated all through the solution |
| Lacks code consistency | Consistent in the way design of the EDW is captured as it also supports consistency of code |
| Lacks portability with continual changes to data platforms | Open-ended, with the design getting captured at the logical level; allows the move from one technology to another |
| Code required at multiple levels for extracting data | Automates data mapping doing away with the need to write code |
| Time-consuming integration of new data sources | Faster time-to-value in terms of new data source integration |
Save person-days for mapping the ETL process, integrate new data sources rapidly, and seize the advantage of leveraging critical data for analytics, BI, and AI solutions, with the Metadata driven ETL.




