
In a turn of events, Data lakehouse is pitched as the novel paradigm heralding a shift in data management. With the prevalence of data lakes (DL) and data warehouses (DWH), why would enterprises home in on the data lakehouse concept?
You can’t theorise before having data at hand, said Holmes. And contrary to that, today, you have mountains of data to work with but find it daunting to theorise. That’s owing to the complex data architecture.
Sample this complicated scenario. An enterprise has many systems including a data warehouse and a data lake to drive diverse data workloads (BI, machine learning, streaming, and data engineering). There is a need for resources with varied skillsets to manage diverse data pipelining and data management. Another concern is the mounting operational costs to manage multiple systems.
What the data silos also do here is:
- Hinder seamless communication
- Trigger data duplication
- Lead to inconsistent data governance & security
- Necessitate increased data movement hindering performance
And then, you have the concept of Data lakehouse to fill the void of a single repository addressing various analytics needs.
Data Lakehouse – A Primer
Data lakehouse is an evolutionary architecture empowering enterprise with the structured analytics facilitated by a DWH on data housed in cost-effective cloud-based data lake. Addressing the drawbacks of capturing, processing, and analysing data in a multiple-solution system, data lakehouse champions the new data management paradigm of using a single data repository for meeting diverse analytics needs.
The concept combines the best of Data lake and Data warehouse to help address the ‘high cost factor’ involved in laying the data to business insights pipeline. A comparison of data lake vs data warehouse will help understand how the ‘ups and downs of DWH and DL’ have influenced the new data lakehouse concept.
Data lake vs Data warehouse
Data lake houses data, but without schema. You can bring raw data comprising structured, semi-structured and unstructured data into a data lake, but you don’t define the structure while capturing data. The lack of structure makes it an ordeal to manage and govern data.
You have schemas in a data warehouse to analyse organized data. But you cannot accommodate unstructured data and media files in a data warehouse. And data management becomes a tedious process at that. More so when you consider the slow progress you make to acquire insights from data. On the flip side, when data increases in a DWH, performance decreases
Now, enterprises are using data lake and data warehouse as separate entities – data lake to store data and DWH to acquire business insights. In another scenario, data warehouse is either embedded into a data lake or DWH and data lake are brought together in a single platform. What stands out is the constant need for ETL engineering between the data lake and the DWH. In all of these scenarios, cost of managing such ecosystems is quite high.
It is where data lakehouse serves as the single platform merging the best of data warehouse and data lakes.
Single Platform for varied Analytics with Data lakehouse architecture
In context, data lakehouse helps set up a single platform to support multiple analytics and BI use cases. The picture below illustrates the layers and the salient components of data lakehouse architecture.
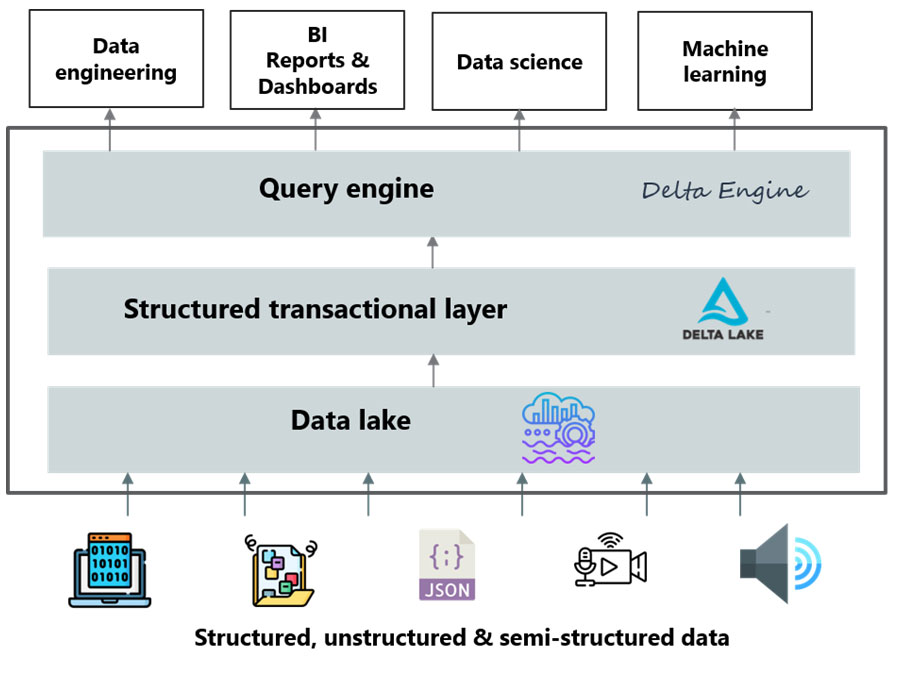
Data lake
Data lake is the starting point for this concept. This sets up the low-cost storage facility to bring in raw data covering structured, unstructured and semi-structured data.
Structured transactional layer
The structured transaction layer strengthens data management by supporting ACID or (atomic, consistent, isolated durable) compliant transactions on big data workloads. With this layer, you can facilitate quicker deletes, updates and schema enforcement. For instance, open source table-format Delta Lake or the metadata layers are used to work with data lakes. The metadata layer sitting on top of the data lake provides the structure you need to govern and manage data lake.
High-performance query engine
The new query engine is the layer meant to bolster performance. For instance, Delta Engine built by Databricks serves this purpose. The query engine is built to enable query acceleration, facilitate SQL search on data lakes.
All analytics workloads
With a data lakehouse, you can run all your analytics workloads. You can use the single data repository to facilitate diverse workloads encompassing machine learning, data science, SQL and analytics.
Benefits of Data lakehouse
To start with, Data lakehouse democratizes data. Enterprises also gain flexibility, cost savings, scalability and increased productivity by embracing the data lakehouse approach. The features captured below help acquire cost and productivity gains.
- Streamlines the complete data engineering architecture
- Acts as common staging tier for all analytics use cases and applications
- Decouples storage from compute resources
- Accommodates and provides access to various data types including audio, video, images, and text
- Uses standardized and open data formats like Parquet, providing direct data access to data science and machine learning
- Empowers with querying of massive unstructured & structured data in quick time
- Enables direct connect between data and analysis tools
- Supports real-time data applications, eliminating the need to have a separate system for real-time reports
- Leverages cost-effective cloud-based storage such as the Amazon S3, Google Cloud Storage and Azure Blob Storage
- Allows use of different query engines like Presto or Spark based on the type of data that needs to be queried
- Uses machine learning tools like PyTorch, TensorFlow and pandas to access sources such as Parquet
- Supports DW schema architectures including snowflake/star schemas
- Empowers by promoting diverse use cases
With the promise of a forward-looking data architecture, future awaits the performance of data lakehouse as an open platform serving all enterprise analytics needs and its ability to meet enterprise expectations.




