
Generative AI champions synthetic data generation. When a Healthtech company realized that imagery data at hand was insufficient for their model, they turned to Synthetic data. By bringing starting-stage tumours with healthy lung imagery together, synthetic dataset was created to get the training dataset that would behave like data belonging to the real-world.
And at the core of the synthetic data is the Generative AI also creating new images, text, music, code or video. Where synthetic data has become a viable option to overcome data scarcity for AI, Generative AI represented by the Generative Adversarial Network (GANs) get to work on a dataset, say that of images. The generator neural network generates new images while the discriminator neural network discriminates the original from the synthetic one, until the synthetically created images don’t get distinguished from the original.
How does Synthetic data address data scarcity for AI and how Generative AI helps generate synthetic data?
Using Synthetic Data to Overcome Data Scarcity for AI
Data scarcity is one of the barriers to AI development; lack of data or difficulty in acquiring high-quality data derails AI projects. Here’s a sample of dataset with skewed balance making it difficult to ensure data is available for minor class.
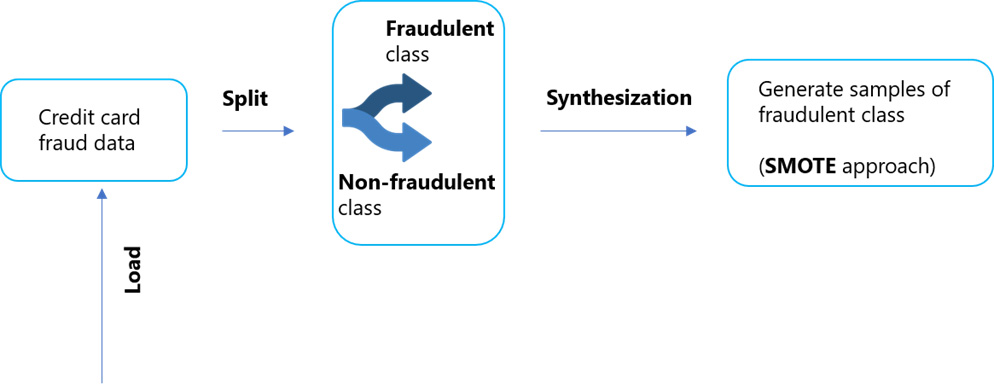
The attempt to find fraudulent credit card transactions was about to be stifled by the imbalance ratio in the dataset – 342 frauds out of 248, 617 transactions, fraud class constituting only 0.137%
Data for a label is very low vs Data for other labels scenario creates data imbalance. Here’s where Synthetic data addresses data scarcity for AI. As data scientists come across non-availability of data, restrictions in processing owing to regulations, synthetic data comes good to replicate the characteristics and patterns of real-world data. With synthetic data, there are no roadblocks to data access, no biases in datasets.
What is synthetic data?
When algorithms are used to generate data (not real-world) from original data, synthetic data takes shape to serve the same purpose that the original data is intended to serve. Synthetic data comes as tabular synthetic data, text synthetic data, and media synthetic data encompassing sound, video or image.
When data is imbalanced, as in the case discussed above, synthetic data becomes useful to increase the data volume while ensuring that the generated synthetic data is similar to the primary dataset. By leveraging SMOTE technique (Synthetic Minority Oversampling Technique), rare labels can be generated from the dataset. For instance, here’s how credit card fraud data can be leveraged to generate sample of the fraudulent class using SMOTE approach, a statistical technique for addressing the imbalance by upsampling the minority class.
Why use Synthetic data?
- Helps create diverse datasets for training machine learning models
- It helps uphold privacy of individuals, protects data privacy
- Empowers removal of PII (personally-identifiable information) from real-world data or other sensitive information while generating synthetic data
- Helps protect PHI (personal health information)
- Helps create high-quality training data while solving underfitting problems in models
- Saves data collection & cleaning time, and data labelling costs
Using Generative AI & GANs for creating Synthetic tabular data
Among the synthetic data types, take synthetic tabular data for instance, and how does Generative AI help create tabular synthetic data?
Sample the tabular synthetic data creation for a marketing campaign. Here the GANs are pressed into action to create synthetic data from the marketing campaign data. For generating synthetic tabular data, GANs and other models including WGAN, CTGAN empower data scientists with tabular synthesis.
While there is a need to create tabular synthetic data, CTGAN or the Conditional Tabular Generative Adversarial Network with the generator/discriminator neural networks is a perfect fit to work with tabular datasets. Leveraging CTGANs, synthetic data can be generated with the same statistical properties as that of the real data. The table below showcases the mix of categorical and numeric features, serving as the original tabular data for the CTGAN to create tabular synthetic data.
| Name | age | Job type | marital | Housing loan | Contacts during campaign | pdays | |
| Peter | 34 | admin | single | Y | 9999999999 | 21 | |
| Sophia | 38 | Self-employed | Married | Y | 7777777777 | 15 | |
| Mark | 32 | Entrepreneur | Married | N | 7676767676 | 42 | |
| Vincent | 41 | technician | single | Y | 5345345434 | 36 | |
| Miriam | 28 | management | Divorced | N | 2345676543 | 20 |
In this case, there is a need to create synthetic data from heterogenous tabular data, CTGANs serve well to work with mixed data across tabular datasets – This is done by addressing specific characters of categorical and well as numerical features and ensuring the generator model is incorporated with the characteristics.
Throwing light on the progress made by CTGAN, here’s how the Generator and Discriminator work in tandem to generate synthetic data.

Generative AI for Data generation in a flash
Now, you can go from Generative AI to synthetic data in a flash. And the Synthetic Data Vault, a Python library with many models like CTGAN and CopulaGAN, helps generate synthetic data from real-world data in quick time. As more and more use cases powered by generative AI unfold, the future of Generative AI technologies could unleash human-like virtual assistant, swift language translation, and spotless document processing among many other applications.




